今回は、Google Search Console(グーグルサーチコンソール) で抑えるべきポイント 【クロールエラー編】です。
理解しやすいよう、先に用語の定義をします。
- クローラー:ウェブ上の文書や画像などを周期的に取得し、自動的にデータベース化するプログラム
- インデックス:ウェブページをクローラーが収集、処理、データベースへ格納するまでの一連のプロセス
1.クローラー
クローラーは、ボット(Bot)、スパイダーなどとも言われます。
検索エンジンのデータベース、インデックス作成に用いられているほか、統計調査などの目的にも利用されます。
クローラーは、文書中に含まれるリンクをたどり別の文書を収集を繰り返します。
また、前回のクロール情報をもとにクロールを開始します。
新しい文書を見つけた場合はデータベースに登録、また既知の文書が存在しないことを検出した場合はデータベースから削除します。
2.インデックス
インデックスとは、『索引』『見出し』『指数』『指標』などの意があります。
Wikipediaでは下記のように定義しています。
索引とは、百科辞典・学術書などの書籍やコンピュータのデータにおいて、特定の項目を素早く参照できるよう、項目を特定の順番に並べ、その項目が出現する物理的な位置をまとめたもの。コンピュータで用いられる際にはインデックス (index)と呼ばれることもある。 ※Wikipedia参照
本来のインデックスは上記の意味がありますが、データベースに関連する際には、格納されたデータをより早く抽出できるように作られたデータベースのことを指します。
SEOでのでインデックスは、クローラーが収集したウェブページを検索エンジンデータベースに格納されることを指します。
『インデクシング』などとも言います。
実際は、クローラーがウェブページのデータを収集した後、そのままの形でインデックスされるのではなく、一旦プログラムにより検索エンジンにとって処理のしやすいデータへ変換する処理が行われ、その変換されたデータをインデックスします。
ここまでで、おおよそクローラーとインデックスをご理解いただけたかと思われます。
今回は、まず管理画面にある情報をしっかりと読み解けることを目標とします。
よって、読み解いた後の解決策は改めて投稿しますので、予めご了承ください。
それでは本編に入ります。
クロールエラーを知るには、Google Search Consoleより確認します。
クロール関連情報を確認する方法として、クロール > クロールエラーがあります。
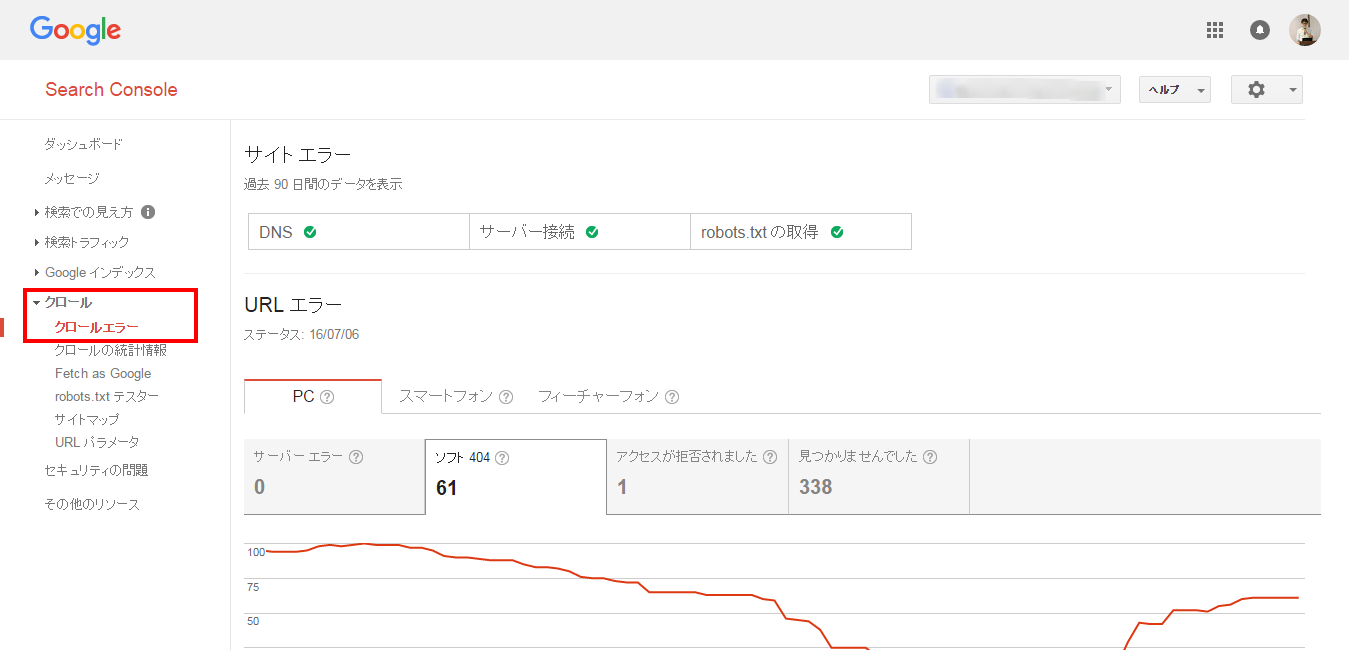
いろいろなタブがありますので、これから1つずつ説明して行きます。
まず、デバイスごとにエラー状況をチェックできます。
それぞれのタブをクリックすると詳細が確認できます。
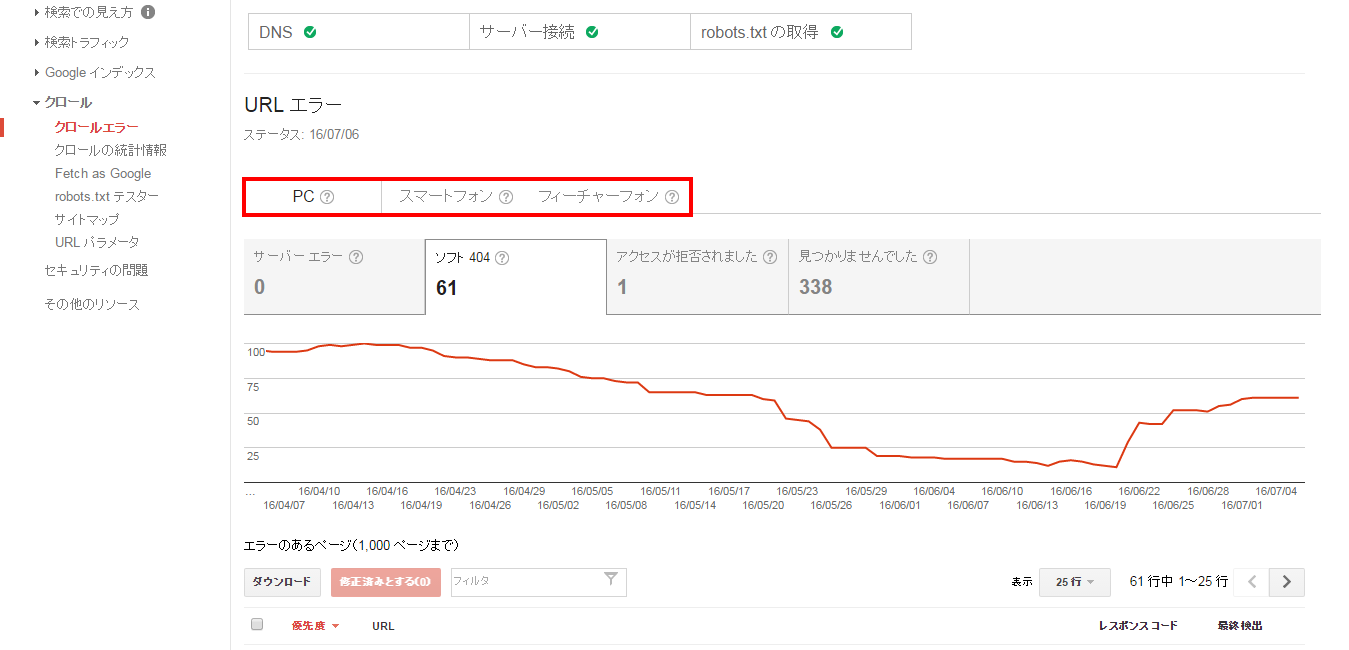
次に、それそれのエラーの詳細を説明します。
- サーバエラー
- ソフト404
- アクセスが拒否された
- 見つかりませんでした
1.サーバエラー
サーバエラーは、サーバーの応答に時間がかかった、クローラーがブロックされてサイトへアクセスできなかったなどの状況を示しています。
具体的には下記のようなエラーになります。
- 接続タイムアウト
- 接続に失敗しました
- 接続が拒否されました
- 応答がありません
- 応答が途切れました
- 接続がリセットされました
- ヘッダーが途切れました
- タイムアウト
各エラーの説明は下記になります。
- 『接続タイムアウト』は、サーバに接続できなかった、サーバーがインターネットに接続されていない、サーバーが過負荷状態になっている、設定が間違っているなどの状態
- 『接続に失敗しました』は、ネットワークへアクセスできない、ネットワークのダウンなどサーバーへ接続できない状態
- 『接続が拒否されました』は、ネットワークへアクセスできない、ネットワークのダウンなどサーバーへ接続できない状態
- 『応答がありません』は、サーバーに接続できたが、サーバーからデータが送信される前に接続が切断された状態
- 『応答が途切れました』は、サーバーに接続できたが、サーバーからデータが送信される前に接続が切断された状態
- 『接続がリセットされました』は、接続がリセットされた、サーバーがGoogleのリクエストを正常に処理したが、サーバーとの接続がリセットされたため、コンテンツが返されていない状態
- 『ヘッダーが途切れました』は、サーバーへ接続できたが、ヘッダーが完全に送信される前にサーバーが接続を切断した状態
- 『タイムアウト』は、サーバーがリクエスト待機中にタイムアウトした状態
上記のエラーの解決策は専門的になる為、次回投稿いたします。
上記のような状態だとまずはご理解いただければと思います。
2.ソフト404
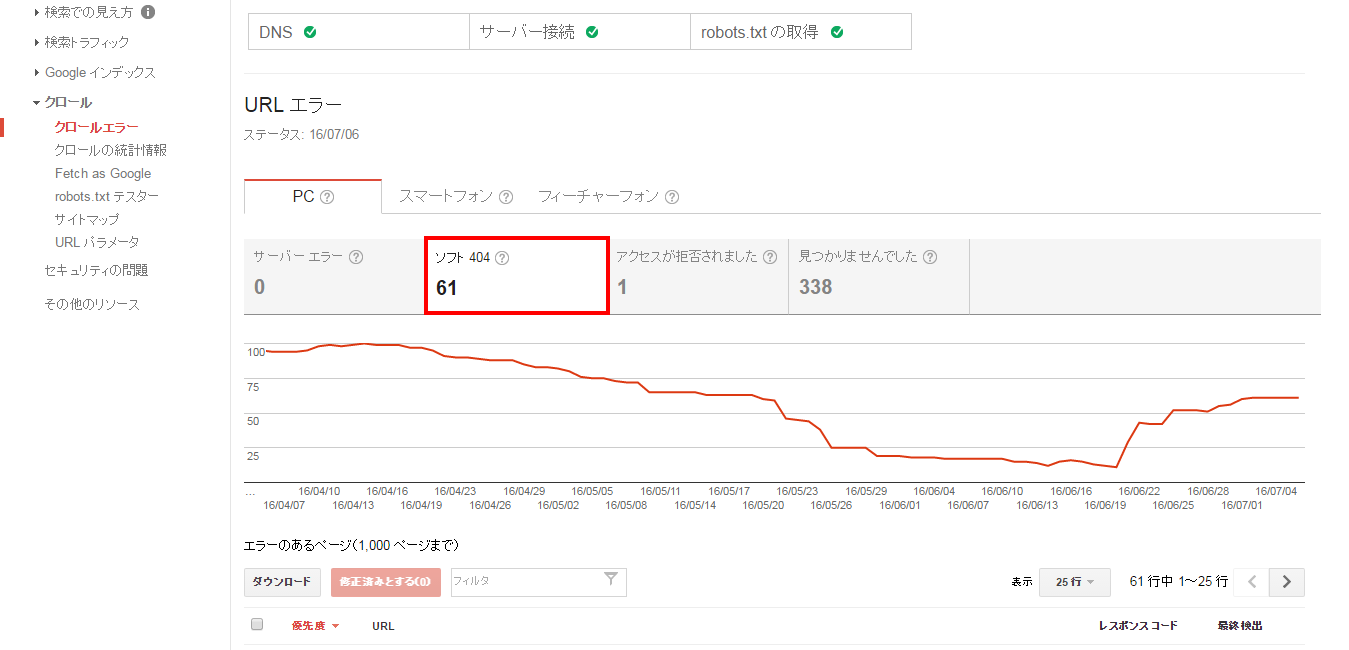
ソフト404は、サーバーにリクエストしたページやファイルがない場合、サーバーからステータスコード404が返されエラーとなります。
このエラーのことを404エラーと言います。
サーバーから返されるステータスコードは下記になります。
- 200:OK (正常)
- 301:Moved Permanently (恒久的に移動)
- 302:Found (一時的に移動)
- 400:Bad Request (無効なリクエスト)
- 403:Forbidden (禁止:ファイルはあるが処理がNG)
- 404:Not Found (見つかりません:ファイルがない)
- 500:Internal Server Error (サーバの内部エラー)
ページやファイルが無いのに404(見つかりません)エラーではなく、200(正常)などを返すエラーが発生している状態がソフト404エラーです。
言い換えれば、ページが存在しないにも関わらず、ページが存在している状態になっています。
サーバーでは、存在しないページへのリクエストに応答する際、404エラーを返すだけでなく、404ページも表示します。
404ページとは「ファイルが見つかりません」と表示されるページのことです。
ページに「ファイルが見つかりません」という 404メッセージが表示されたとしても、そのページが404ページであるとは限りません。
存在しないページに対してクローラーの時間が消費されること、また検索結果に対して「ファイルが見つかりません」を表示させることは、Googleの検索エンジンの質を落とすことになる為、それらを上位に表示させたくないことは、ご理解いただけるかと思います。
上記問題を解決するには、存在しないページへのリクエストに応答する際に、404エラー(見つかりません)または 410エラー(存在しない)として返すことです。
そして独自の404エラーページを表示させるようにすることです。
詳細はまた改めて投稿いたします。
3.アクセスが拒否された
アクセスが拒否されたとは、クローラーが何かしらの原因でページにアクセスできなかったことを指します。
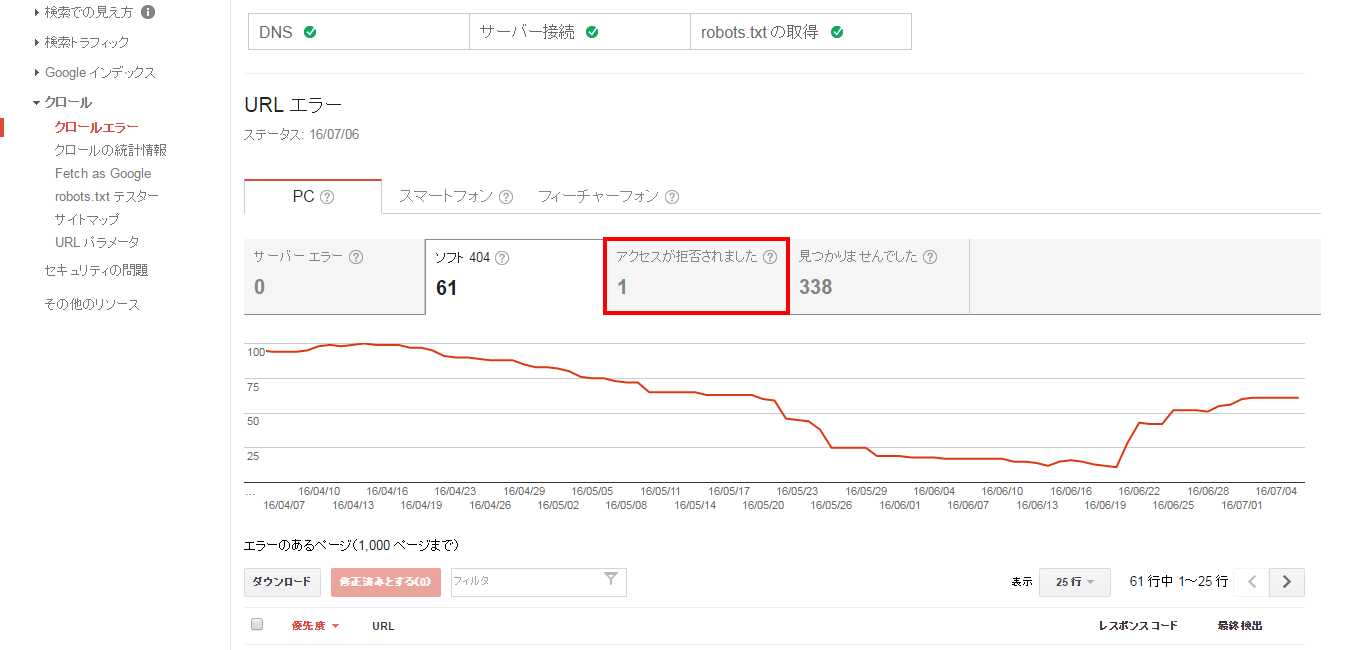
robotx.txtファイルによりクローラーをブロックする設定になっていないかを確認する必要があります。
意図してアクセスができない状態であれば問題ありませんが、意図しない状態の場合は調査する必要があります。
こちらの解決策は専門的な話になりますので、社内担当者又は委託先の制作会社へ相談しましょう。
こちらの詳細も次回改めて投稿いたします。
4.見つかりませんでした
見つかりませんでしたとは、404エラーのことで、サーバー側から受け取るエラーコードのことです。
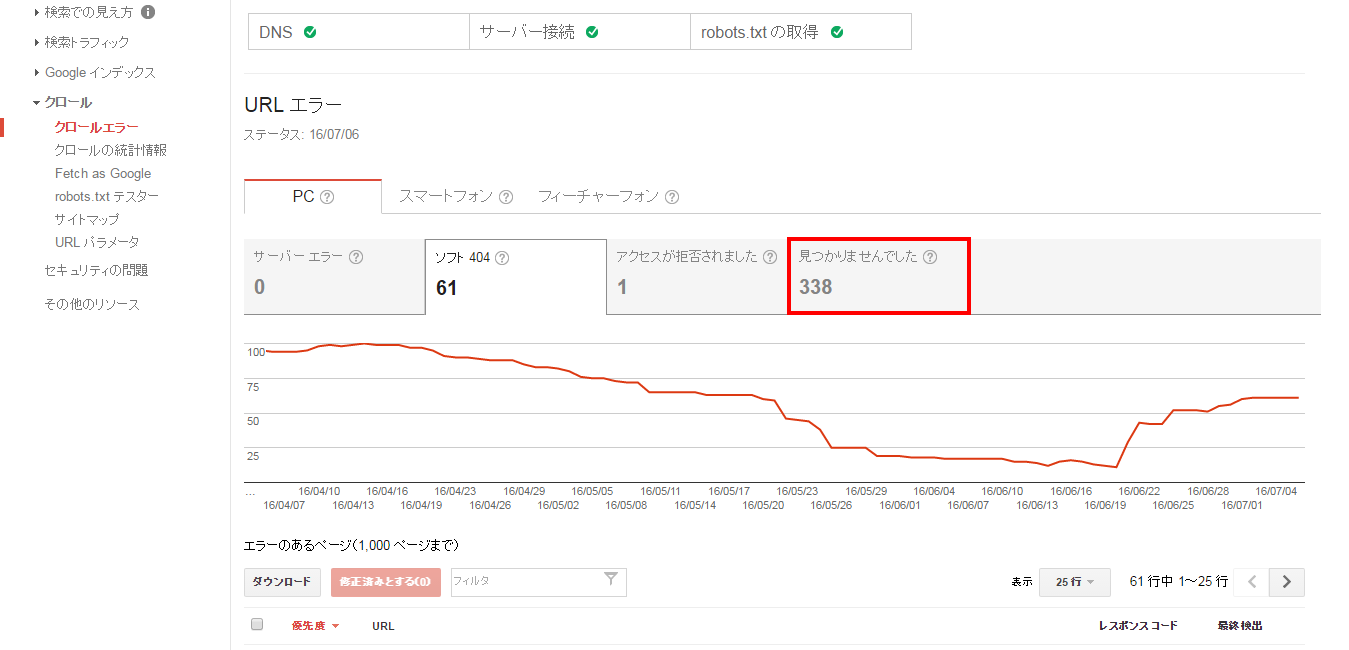
なぜ、存在しないページがあるのか。
いろんな状況がありますが、例えばウェブサイトへリンクをもらっている状態で、リンク元を調べずにサイトリニューアルした際に、リンクをもらっているページを削除した場合など、リンク元が残っていますが、ページが存在しない状況になります。
他にも、ウェブサイトからたどれないが、インターネット上にページが残っている状況など。
解決するには、まず一覧に表示されたURLをクリックして、リンク元を確認します。
リンク元が御社のウェブサイトからのリンクであれば、修正・削除しましょう。
もし外部のウェブサイトからのリンクがあった場合、301リダイレクトを設定して、元のページに類似した内容のページへ誘導しましょう。
301リダイレクトとは、ドメインやURLを恒久的に変更す際に使用される手法です。
こちらの詳細もまた改めて投稿します。
今回の目標は読み解けるまでですが、いかがでしたでしょうか。
まずこちらをご理解いただけないと、各解決策を読み解いていくには苦労されるかと思います。
理由に、デザイナーやコーダーのプロでもわからない、サーバ側の話が中心になるからです。
もし興味がありましたら、次回の投稿をご覧いただければと思います。
- 投稿タグ
- グーグルサーチコンソール

